

Filmovi i SF
Alfred Hitchcock (13. kolovoza 1899. – 29. travnja 1980.) bio je britanski filmski redatelj. Vjerojatno su rijetki oni koji nisu čuli za ovog filmskog...
Pozdrav, koji sadržaj vas zanima?


Ako ste se ikada uhvatili kako ChatGPT-u govorite „molim“ i „hvala“, niste jedini. U neformalnoj internetskoj anketi koju je proveo Ethan Mollick, profesor na...
Alfred Hitchcock (13. kolovoza 1899. – 29. travnja 1980.) bio je britanski filmski redatelj. Vjerojatno su rijetki oni koji nisu čuli za ovog filmskog...


Kate Winslet (rođena 5. listopada 1975.) engleska je glumica. Poznata je po ulogama u povijesnim dramama, kao i po složenim likovima koje često utjelovljuje....

Majčin dan se bliži. Kako odabrati poklon za ženu koja vam je podarila život ili za ženu koja vam je podarila djecu? Može li...


Leonardo DiCaprio (rođen 11. studenog 1974.) nesumnjivo je jedan od najpoznatijih američkih glumaca naše generacije, ali i jedan od najvećih glumaca u povijesti filma....


Zamislite da ste izašli iz kuće i tek nakon nekoliko minuta shvatili da ste zaboravili mobitel. Osjećaj nelagode se javlja odmah – kao da...

Postoje određeni zanimanja u kojima je posebno važno paziti na profesionalan izgled , a zdravstvena djelatnost je savršen primjer. Prvi dojam je ovdje važniji...


Tražite ideje za rasprodaju za Valentinovo kako biste proslavili ljubav i tehnologiju? Godeal24 rasprodaja za Valentinovo nudi sve što vam treba! Bilo da darujete...


Blagdani su možda završili, ali Godeal24 ne prestaje s ponudama ušteda. Na ograničeno vrijeme, njihova posljednja, manje poznata rasprodaja – Posebna zimska ponuda softvera...

Google je uveo novu sigurnosnu značajku u svoj mobilni operativni sustav Android kojom će se uređaj automatski ponovno pokrenuti ako ostane zaključan tri uzastopna...


Započnite blagdane uz iznenađenja povodom globalnog dana lansiranja Blackviewa! Kao jedan od najbrže rastućih tehnoloških brendova, Blackview nudi rane popuste do čak 56% na...


Za korisnike robusnih pametnih telefona, izazovi ekstremnih okruženja stalni su suputnici. Od zaglušujuće buke na gradilištima do potpune tame divljine, te od hitnih spašavanja...


Avanture na otvorenom i rad u zahtjevnim okruženjima često dolaze s izazovima — jedan ekran koji ne podržava multitasking, loše osvjetljenje, usporene performanse i...

Različiti čimbenici iz okoliša poput UV zračenja konstantno stvaraju takozvane slobodne radikale u našem tijelu. To je apsolutno normalno i samo po sebi nije...


Znanstvenici su nedavno otkrili do sada neviđeni oblik kisika, čije bi ponašanje moglo dovesti u pitanje postojeće teorije nuklearne fizike o “magičnim brojevima”. U...


Kisele kiše, fenomen koji je postao sve prisutniji u modernom ekološkom diskursu, intrigantna su i složena tema koja zaslužuje pažljivu analizu. Iako naziv “kisele...


Borove iglice. Dim. Snijeg. To su mirisi koje najčešće povezujemo sa zimom. Ali zašto se uopće miris zime razlikuje od mirisa ljetnih vrućina? „Jedan...


Zaboravite na slatke, kockaste avatare – Roblox je postao puno više od dječje igre. Igrica je prepuna horor naslova koji mogu ozbiljno testirati vaše...

Ako ste ikada tražili slot igru koja kombinira klasičnu jednostavnost s mogućnošću ozbiljnih dobitaka, vjerojatno ste naišli na naziv Sizzling Hot. Ova slot igra,...


Zima je tradicionalno najoštrija u drugom mjesecu. Zbog hladnoće i kratkih dana obično imamo više slobodnog vremena nego inače. Tada je najbolje skuhati čaj,...

Srednja klasa pametnih telefona dobila je novog, ozbiljnog izazivača. HONOR 90 dodatak je ionako već jakoj ponudi uređaja iz njihovih tvornica. Riječ je o...


Best-buy kategorija pametnih telefona jako je elastičan pojam. Nekada su to bili uređaji s cijenom između 150 i 200 eura, ali danas stvari stoje...


Bežične slušalice postaju sve bolje. Nekad se za dobar gadget morala opljačkati banka, danas ga kupiš za par stotina kuna. Baš zato pišem recenziju...

Potreba za memorijskim prostorom sve je veća. Početkom 2000-ih imali smo računala čiji je hard disk rijetko prelazio 40 GB kapaciteta. Ako se danas...
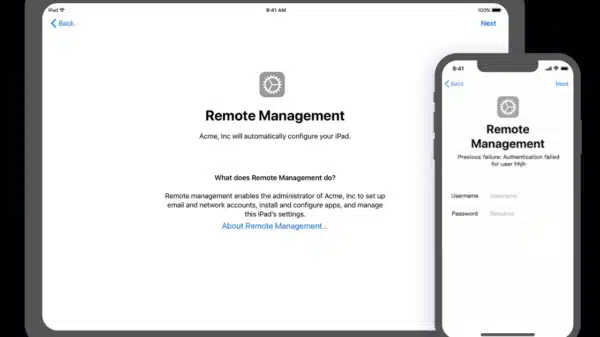
Naši Apple uređaji pohranjuju sve, od lozinki naših bankovnih računa do dragocjenih obiteljskih fotografija s rođendana, vjenčanja i drugih proslava. Zato je uznemirujuće kad...


Iako Apple uređaji slove za vrlo kvalitetne uređaje, većina iPhone ili iPad korisnika tijekom svog života susrela se s bar jednim od sljedećih problema:...

Svi znamo da zlonamjerni softver postoji. Zlonamjerni softver uključuje aplikacije koje vas špijuniraju, kvare vaše podatke, uništavaju vaš tvrdi disk ili daju kontrolu nad...


Novo računalo obično djeluje sjajno i uzbudljivo, osim kada dolazi prepuno dodatnog softvera koji nikada niste tražili – poput probne verzije McAfee antivirusnog softvera....


Svatko uživa u dobrom podcastu ili popisu za reprodukciju isporučenom putem AirPoda, bežičnih slušalica. Ono što ne volimo je odvratno, ljepljivo smeće koje se...

JAMining, vodeća svjetska platforma za rudarenje kriptovaluta, održala je govor pod nazivom “Uspon i izazovi kriptovaluta”, u kojem je analizirala trenutačno stanje i buduće...


WhiteBIT, vodeća burza kriptovaluta, jača svoju međunarodnu prisutnost osiguravanjem VASP (Virtual Asset Service Provider) licenci u Hrvatskoj, Italiji i Kazahstanu. Ovaj strateški potez omogućuje...


U današnjem digitalnom dobu, kriptovalute postaju sve popularnije kao sredstvo plaćanja. Sa sve većim prihvaćanjem Bitcoina, Ethereuma i drugih digitalnih valuta, potražnja za sigurnim...

Tvrtka Take-Two Interactive u petak je odgodila izlazak igre Grand Theft Auto VI do 26. svibnja 2026., čime se dodatno produžuje čekanje na jedan...


Prije nekoliko tjedana na App Storeu pojavila se nova aplikacija pod nazivom Lately, posebno osmišljena za osobe koje imaju poteškoća s organizacijom vremena, poput...


WhatsApp je u srijedu najavio pokretanje nove značajke koja će korisnicima omogućiti dodatni sloj privatnosti u razgovorima. Nova postavka pod nazivom “Napredna privatnost razgovora”...


U nedjelju je 21-godišnji Chungin “Roy” Lee objavio kako je osigurao 5,3 milijuna dolara početnog ulaganja od investicijskih fondova Abstract Ventures i Susa Ventures...


Nedavno lansirani AI modeli o3 i o4-mini iz OpenAI-ja predstavljaju vrhunac tehnološkog razvoja u mnogim aspektima. Ipak, unatoč napretku, ovi novi modeli i dalje...


Instagram je nedavno predstavio novu značajku pod nazivom Blend, koja korisnicima omogućuje stvaranje personaliziranog feeda Reels videa namijenjenog dijeljenju s prijateljima. Ova funkcionalnost omogućuje...


Danas često viđamo digitalne trgovine s ponudom igara, knjiga i glazbe. Brzo, lako i iz udobnosti svoga doma možemo kupovati, preuzimati i upotrebljavati. No,...


U svijetu u kojem informacije nikada ne prestaju dolaziti, a vijesti se osvježavaju u stvarnom vremenu, navika neprekidnog pregledavanja negativnih sadržaja postala je prepoznatljiv...


OpenAI je početkom tjedna predstavio novu generaciju svojih modela umjetne inteligencije pod imenom GPT-4.1, koja uključuje varijante mini i nano. Ovi modeli posebno su...


Zadržavanje vrhunskih stručnjaka za umjetnu inteligenciju postaje sve teže u sve oštrijoj konkurenciji između Googlea, OpenAI-a i drugih velikih tehnoloških kompanija. Prema pisanju Business...